All the databases
18th Jul 2018
Originally posted on our ‘Base’ Medium account.
In September 2019, Base became Passenger.
The database landscape was largely unchanging years ago. There was still innovation but it stayed tethered to SQL. SQL was king. DBAs wrote stored procedures and DevOps hadn’t been born. At this time there was a 90% chance you had a single database architecture that was either Microsoft SQL, Oracle or MySQL.
Times changed and people started talking about CAP instead of ACID. The idea of NoSQL came along and new database engines popped up almost as often as new JavaScript frameworks. Today, software teams have a vast choice of database systems to choose from.
Passenger is made up of many services (not quite microservices) and various database systems. When chatting about our tech stack to other PHP developers it takes a while to get through the list and explain the reasons behind them. We often forget about some of them too, as in many cases they’re sitting there in the background, doing reads and writes all day long without complaining.
If you’re interested in the “why” behind some of the tech at Passenger then read on…
MongoDB
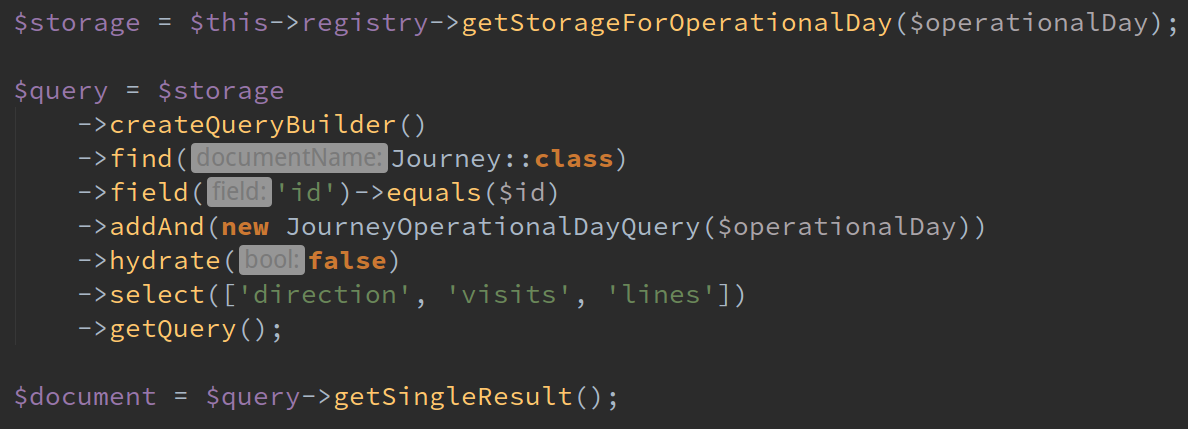
Almost all our transport data is stored in MongoDB. Mongo falls under the “NoSQL” class of databases and is document-orientated. Mongo lends itself well here as public transport journeys are discrete objects with lots of data. To fetch a timetable, we look for all the journeys in that timetable. This is much simpler than storing individual times as rows in a SQL database as it means things like journeys crossing midnight aren’t a special case.
A benefit working with fixed timetables is that there is a whole sub-domain of data that rarely changes. This means we can focus on having simple and performant read structures. We do this by performing the more intensive writes as a series of background import jobs. Any time we want a new view on the data that existing documents don’t lend themselves to, we can add a new job to import data in a different way.
MariaDB
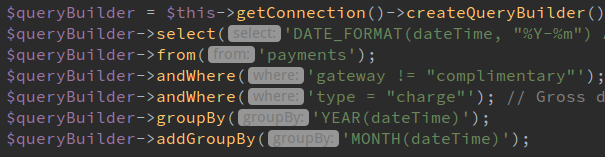
Ticket products and payments are stored in MariaDB. The relational nature of it allows for various different views and reports to be created and its atomicity is suitable for payment transactions.
Elasticsearch
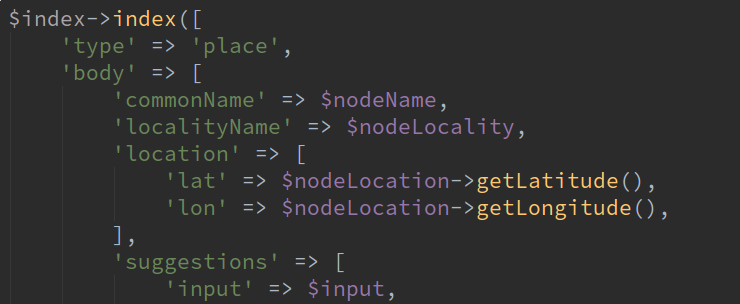
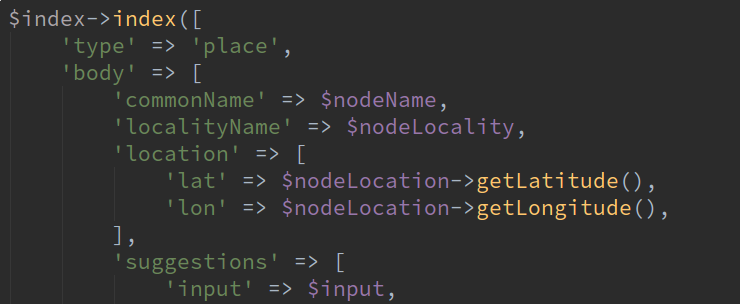
Elasticsearch is a search engine. We, of course, use it for searching. This powers things like the auto-complete results in Passenger apps and websites. Google is very good at search too but Elastic allows us to fine tune what data goes in and what data is returned in search results, prioritising locations that can be reached via each transport network.
Redis
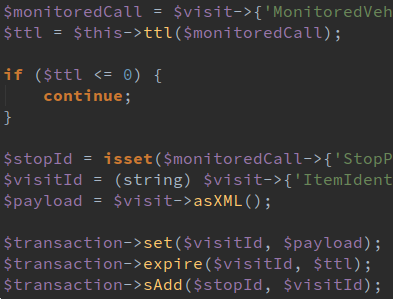
We use Redis for real time transport data, such as stop departures. Redis’ built in timed expiry of keys is perfect for automatically cleaning out data. Being in-memory, Redis is very fast, which allows us to serve departure boards for many thousands of stops in just a few milliseconds.
DynamoDB
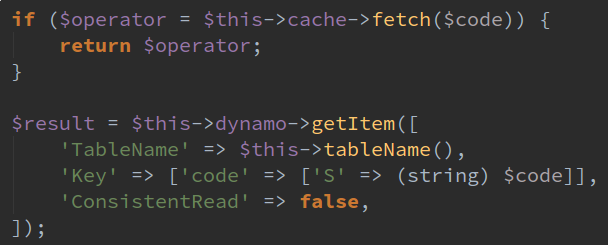
Amazon’s DynamoDB is used as Passenger’s configuration. Distributed services can access parts of the same config over the internet. We have a package used in each service that fetches the config for the service in a uniform way.
Graphs
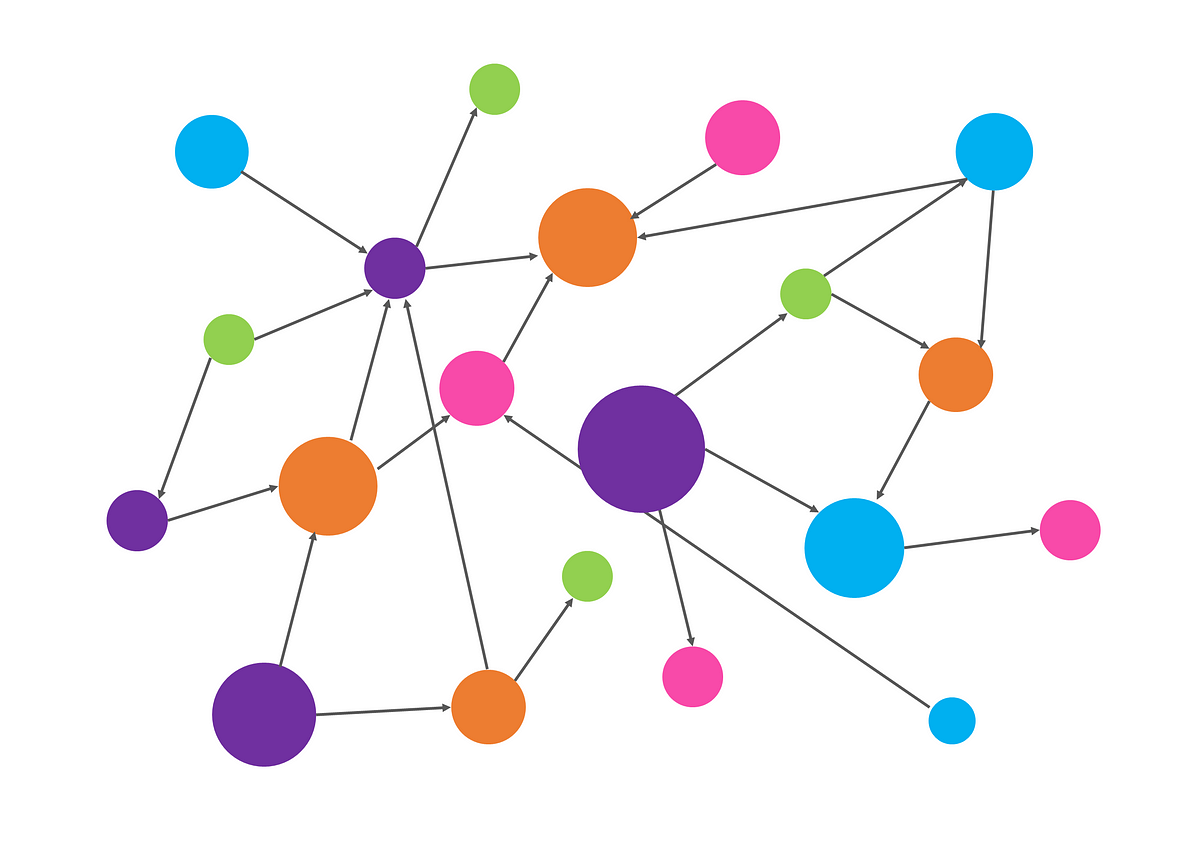
Getting more esoteric, we also have an in-memory directed graph of journey data. This allows us to plan journeys across nodes a transport network, querying based on geospatial and temporal constraints.
We’ve built 2 of our own journey planners from scratch in the past but Passenger now uses OpenTripPlanner behind the scenes, with our own data augmentation and processes going on too.
At first glance having so many different databases may look like overcomplexity. In reality, the storage engines have clear responsibilities and contexts in which they use the data. The isolation means we haven’t ended up with one monolithic SQL server that gets out of control.
Having 6* different databases can be a bit of a learning curve for new developers. Fortunately, PHP packages like Doctrine abstract away many of the differences. Ansible and Terraform (for provisioning servers and development environments) helps here too, as new instances can be created without having to configure anything.
There’s various bits we’re expecting to change in the future. There’s a good chance we’ll outgrow Redis for some of the real-time things we want to do and have to move that elsewhere. We’ve only scratched the surface of Elastic, so want to exploit more of its capabilities to provide a better UX. More of our storage is heading towards AWS too, to make scaling easier and so we can focus on the code.
*At the current count, not including storage used by websites and apps — that will have to be a separate post.
Share this article

Newsletter
We care about protecting your data. Here’s our Privacy Policy.
Related news
Start your journey with Passenger
If you want to learn more, request a demo or talk to someone who can help you take the next step forwards, just drop us a line.