Developing an API to Highlight Inaccuracies in UK Open Data
19th Feb 2019
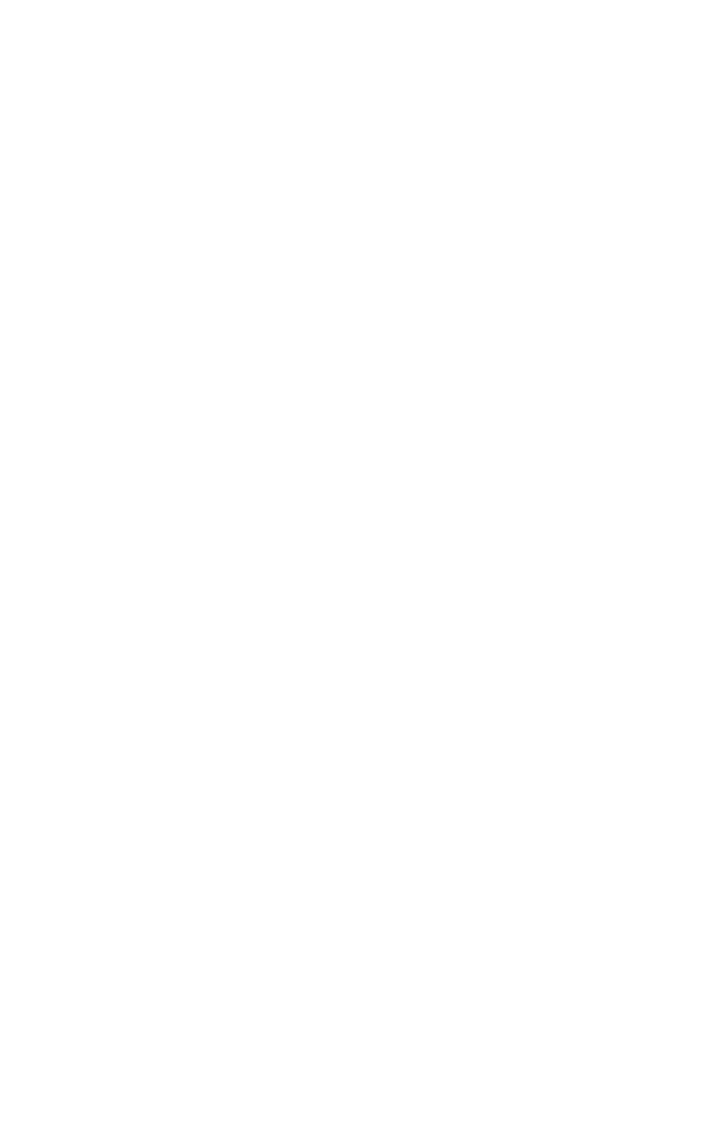

Originally posted on our ‘Base’ Medium account.
In September 2019, Base became Passenger.
Bus Stop Checker was the first project on which I took the reins at Passenger.
Originally kicked off by Manuel Martin Salvador, a former employee, Bus Stop Checker was an initiative launched to visualise potential errors in the National Public Transport Access Nodes (NaPTAN) database. We suspected that this set of open data, which contains information about all bus stops and other points of access to public transport around the UK, involved numerous inconsistencies. We wanted to make these inconsistencies undeniable and evident.
The original reason for the initial development work was to better calculate journey ETAs for our Passenger products. Things started to shift as we discovered discrepancies, and the project evolved into what the Bus Stop Checker is today.

Manuel had written a Python script which calculated the road bearing of a stop in NaPTAN against OpenStreetMap (OSM) for Dorset. When it started to throw up potential errors, we began plotting them using Google Maps. This was a useful experiment as it clearly illustrated that something was wrong with the NaPTAN data — and confirmed the feedback we had previously received from end-users of Passenger mobile apps.
At this stage, that was all this was — an experiment. However, the Passenger team wanted to scale these findings into something that could effectively show that NaPTAN problems existed across the whole of Great Britain, in an easily searchable and penetrable way. The hope was that the results of the project would spark discussion around the dataset and get people thinking about how it could be improved. Passenger could then be brought into the discussion around the upkeep of NaPTAN data — which largely occurred behind the seemingly inaccessible walled garden of local transport authorities.
Read a more thorough introduction to the Bus Stop Checker project
The Python script

Manuel’s Python script would follow this process:
- Loop through nodes in the OSM data file and import these nodes into MongoDB
- Loop through each NaPTAN stop in MongoDB
- Find the closest 4 OSM nodes to the stop using OSRM over HTTP
- Try to match a road name in OSM to the one in NaPTAN using the Levenshtein distance
- Calculate the bearing of the road and the bus stop and output this data in a CSV
Armed with this Python script, I set out to build Bus Stop Checker.
I started by updating the script’s dependencies (mainly PyOsmium and PyMongo) and fixing the script so it could once again work for Dorset. The next step was to download the larger Great Britain dataset and see how the script would cope with it.
7 hours or so later the Osmium Python bindings had crashed, but we had substantially more data to work with than before: Around 35% of the whole of Great Britain. When sifting through this data it was clear there were substantial errors in the dataset. The Google Maps front-end just about managed to render this chunk of data (every single stop at once) and provided some useful feedback around edge cases that would require a little more scrutiny.
Addressing issues
I now had more substantial data, which was great, but this also made it difficult to uncover issues using the old Google Maps viewer. I decided to write an API using PHP (the primary server-side language Passenger and Base use) which would import this data into PostgreSQL. This presented some endpoints our front-end team could use to start building an early Bus Stop Checker prototype user interface.
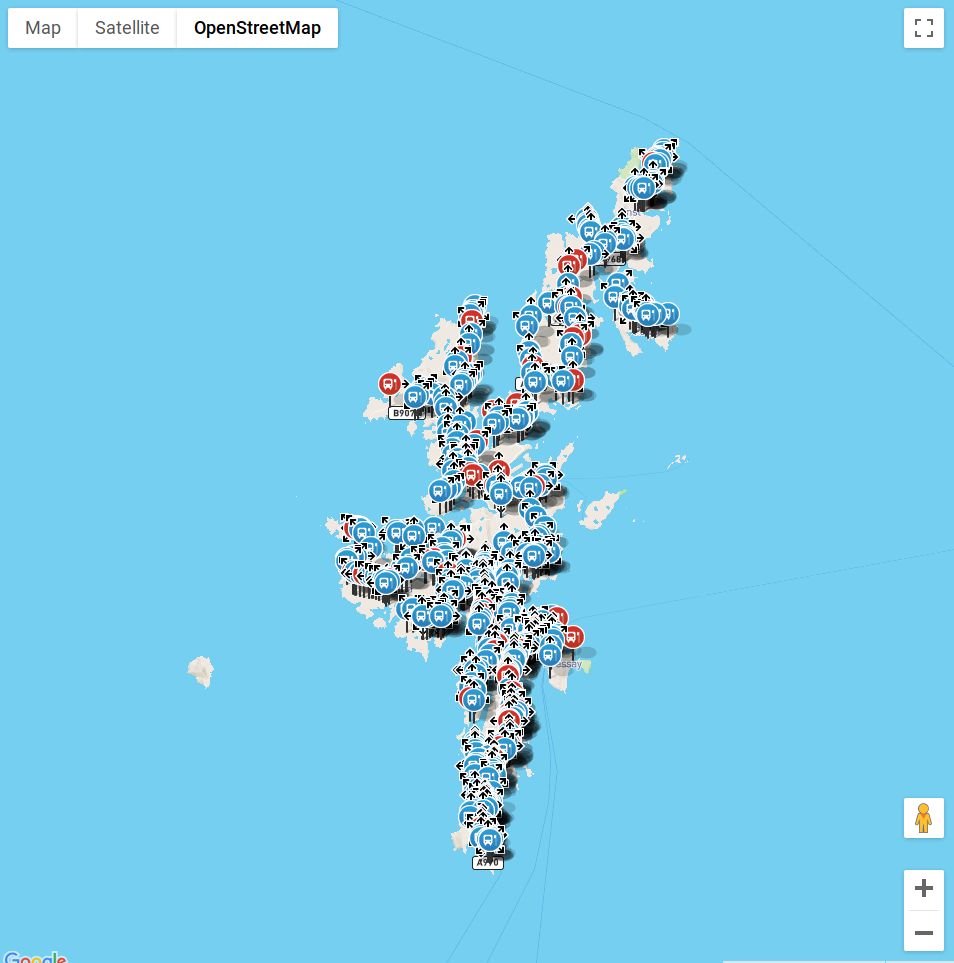
Once we had an early front-end version of Bus Stop Checker, we could start looking for issues and address them.
For example, at this stage, the Python script for Bus Stop Checker would obtain the 4 closest OSM nodes to any given stop location — but this was sometimes not enough.
‘Nodes’ are the points of data which make up a ‘way’, a ‘way’ is the road on which these points are located. Some ways are defined by very few nodes, others by many. By obtaining only the 4 closest nodes we would often not return enough data to match the correct road, as a nearby road (but not the actual road NaPTAN says it’s on) may have many incredibly detailed points, and thus would return false data.
I fixed this by collecting all nodes within a fixed radius around the stop, rather than just the closest 4. I also improved the error handling of the script by storing its last processed stop and continuing from that stop in the event a failure occurred.
At this point I re-ran the script on the OSM data for Great Britain.
Improving the process
16 hours later the script had finished and was producing more accurate results. Further investigation of the new data showed that the Python Osmium bindings were still rather unreliable for a production system, so at this point I started researching other options.
I decided to use NodeJS, as it has official OSRM and Osmium bindings, would remove our reliance on the Python bindings and would also eliminate the overhead of the HTTP call to OSRM, thus speeding up processing.
I wrote the NodeJS project closely matching the Python script, with some changes:
- Directly reading the NaPTAN CSV rather than importing into MongoDB first
- Using LevelDB rather than MongoDB for increased speed
- Directly writing the results into PostgreSQL rather than into a CSV
- Multi-threading the verification process: each stop would be read by the main thread and passed to a free child thread, where the actual processing would happen (this greatly improved performance)
- Outputting to a file using protocol buffers for efficient historical logging
The final project using the NodeJS bindings produced far more reliable results, and in an average of 53 minutes for the whole of the UK!
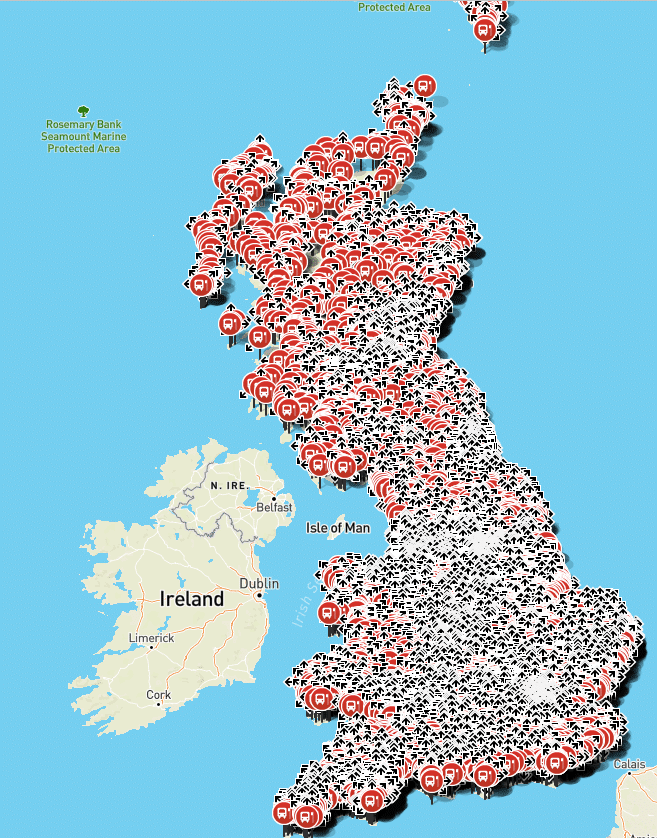
Now I had to get this project running at a regular interval with production reliability — not an easy task.
I created an Alpine Linux-based container which would pull in the OSM data and process it ready for OSRM. I also set up a container that would run the NodeJS project and perform the verification. I loaded these containers into Amazon Web Services’ ECS, added some job definitions, job queues and compute environments for AWS Batch and created some AWS CloudWatch rules to trigger the containers on the last day of each month.
Some further tweaks to the algorithm, including expanding the API to give the front-end team all the data they required, and Bus Stop Checker was complete.


The project spanned 3 programming languages in the end: Python, PHP and NodeJS, and was ultimately a complete success. Since launch, Passenger has been involved in discussions with the Department for Transport about how to improve the NaPTAN dataset and some local transport authorities have actually used the tool to improve their area’s data.

It’s been extremely heartening to see the development work on Bus Stop Checker produce real results that will improve the public transport experience for people all across the UK.
Share this article

Newsletter
We care about protecting your data. Here’s our Privacy Policy.
Related news
Start your journey with Passenger
If you want to learn more, request a demo or talk to someone who can help you take the next step forwards, just drop us a line.